What is it?
|
Automatic Speech Recognition (ASR) allows people to interact with a computer interface using just their voice.
The most advanced ASR technologies use Natural Language Processing (NLP), which gives meaning to the text converted from speech. NLP can reach an accuracy of 96-99%. Speech recognition technology is constantly improving its comprehension of speech with the help of users through Tuning and Active Learning. As speech recognition technology improves with more data, so do voice user interfaces (VUIs) and user experience. |
|
Variants of ASR
|
|
There are two types of Automatic Speech Recognition software variants: directed dialogue conversations and natural language conversations.
Directed dialogue conversations contain interfaces that provide a limited number of responses. These include the automated interfaces for customer service lines that ask the caller to press or say a specific number corresponding to a request. Natural language conversations use an open-ended chat format to better simulate a real conversation. These can be seen in virtual assistants like Siri, OK Google, Alexa and Cortana. This video demonstrates one of the first customer-facing speech recognition systems developed at AT&T Bell Labs that uses natural language. |
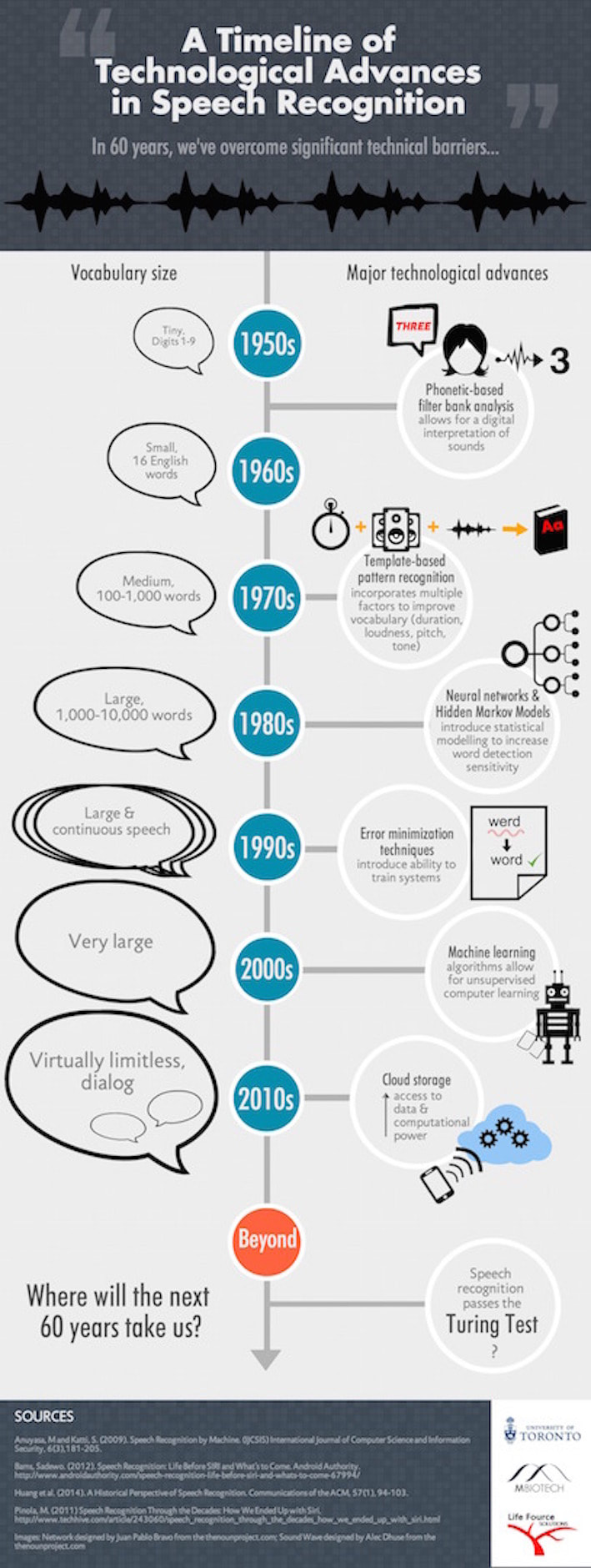
How Does it Work?
|
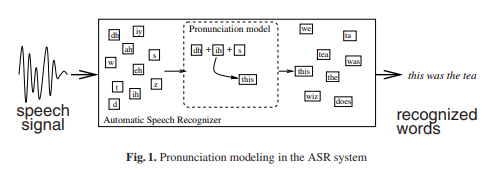
Speech recognition uses acoustic and language modeling algorithms. Acoustic modeling refers to the process of establishing statistical representations for the feature vector sequences (e.g. meaningful graphs) computed from the speech waveform. This waveform can easily be analyzed after background noise is reduced and volume is normalized.
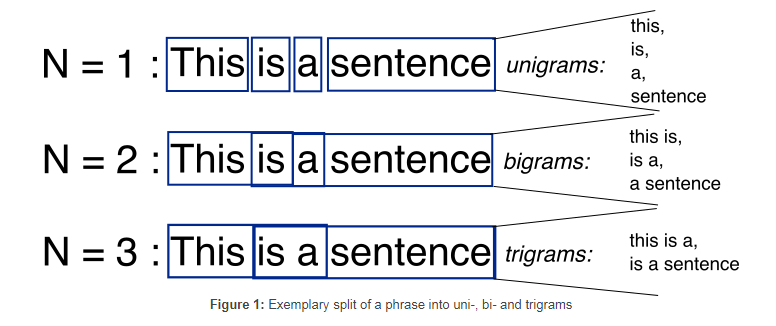
Acoustic modeling also involves pronunciation modeling, where a sequence of fundamental speech units, phonemes, represent larger speech units like words and phrases. There are many acoustic models, the most common type being the Hidden Markov Model (HMM), invented in 1970. Others include segmental models, super-segmental models, neural networks, maximum entropy models, and hidden conditional random fields. Language modeling algorithms assign probabilities to sequences of words. They are often used for speech to text applications. The simplest model that assigns probabilities to sequences of words is the N-gram, which is a sequence of N words (e.g. a two-word sequence is a 2-gram or bigram; a three-word sequence is a 3-gram or trigram). |
|
Basic speech recognition software has a limited vocabulary of words and phrases, and it may only identify these if they are spoken clearly. More sophisticated software has the ability to accept natural speech. The process of speech recognition developing from the former to the latter can be seen below.